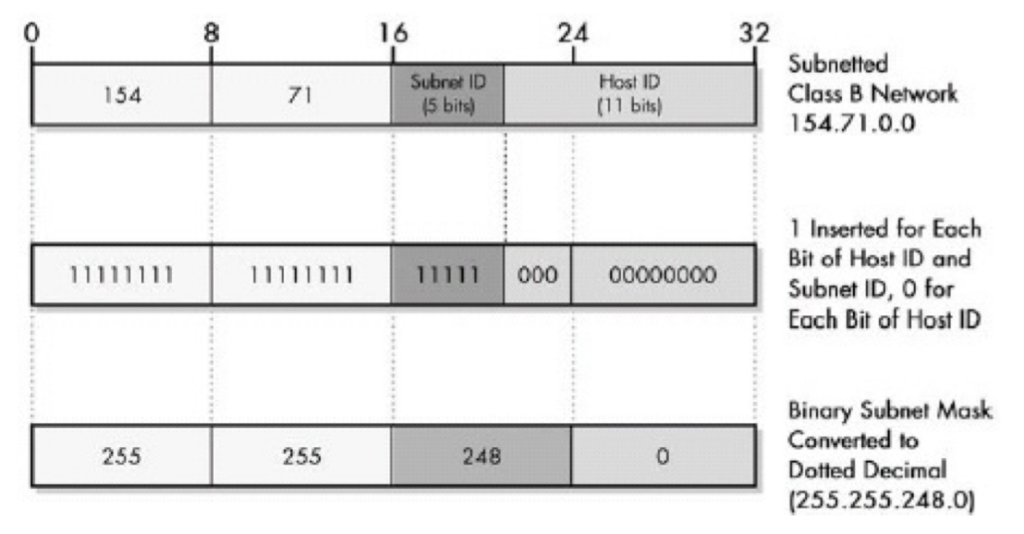
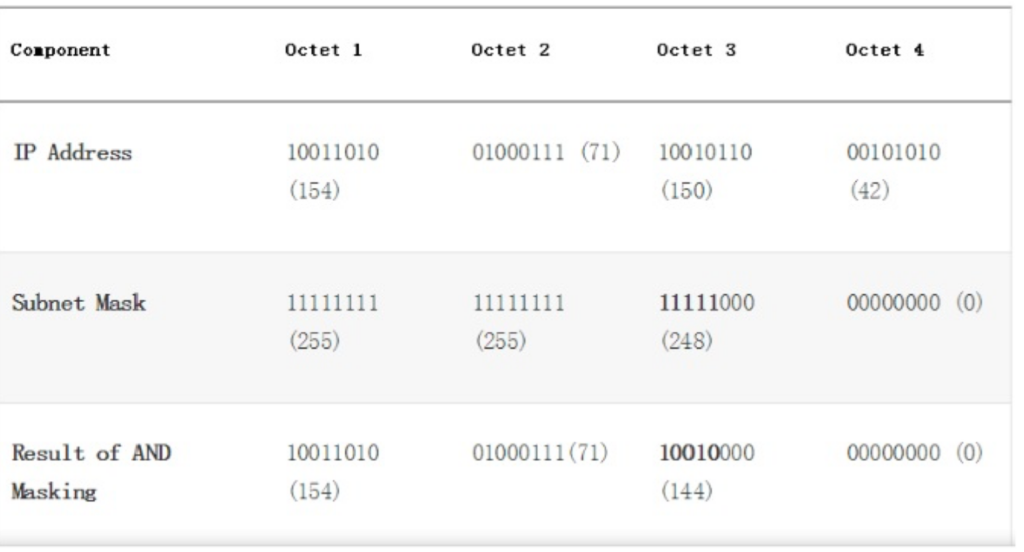
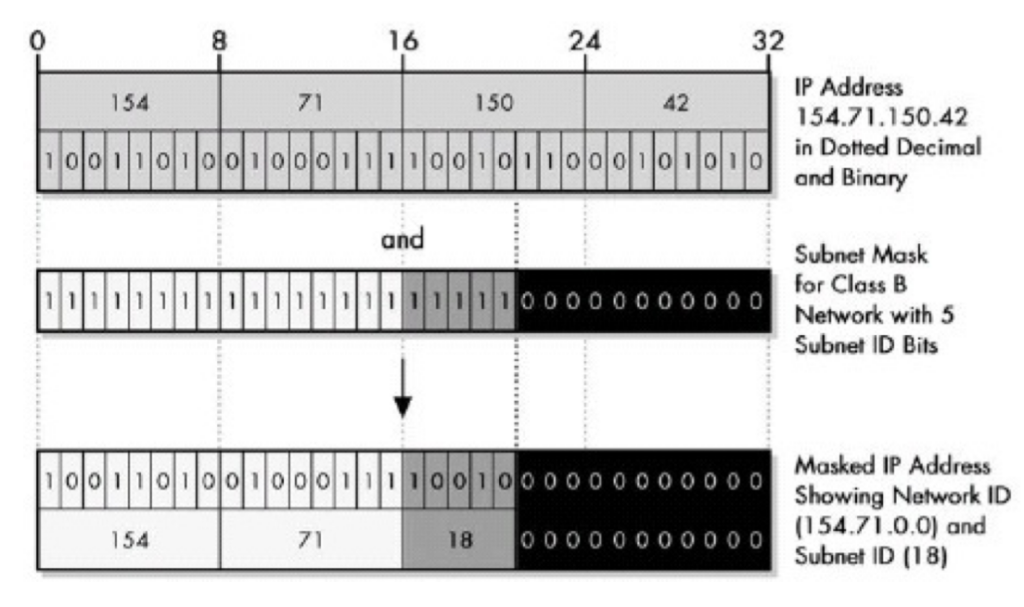
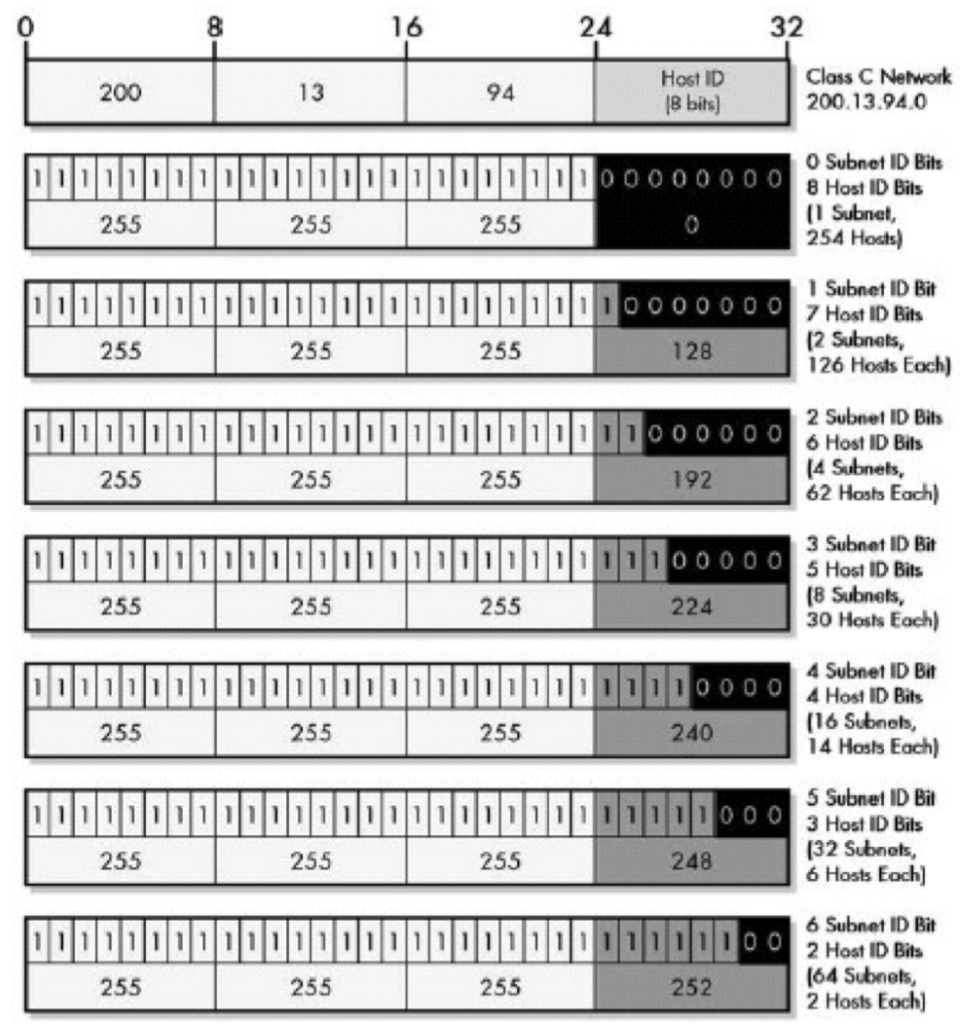
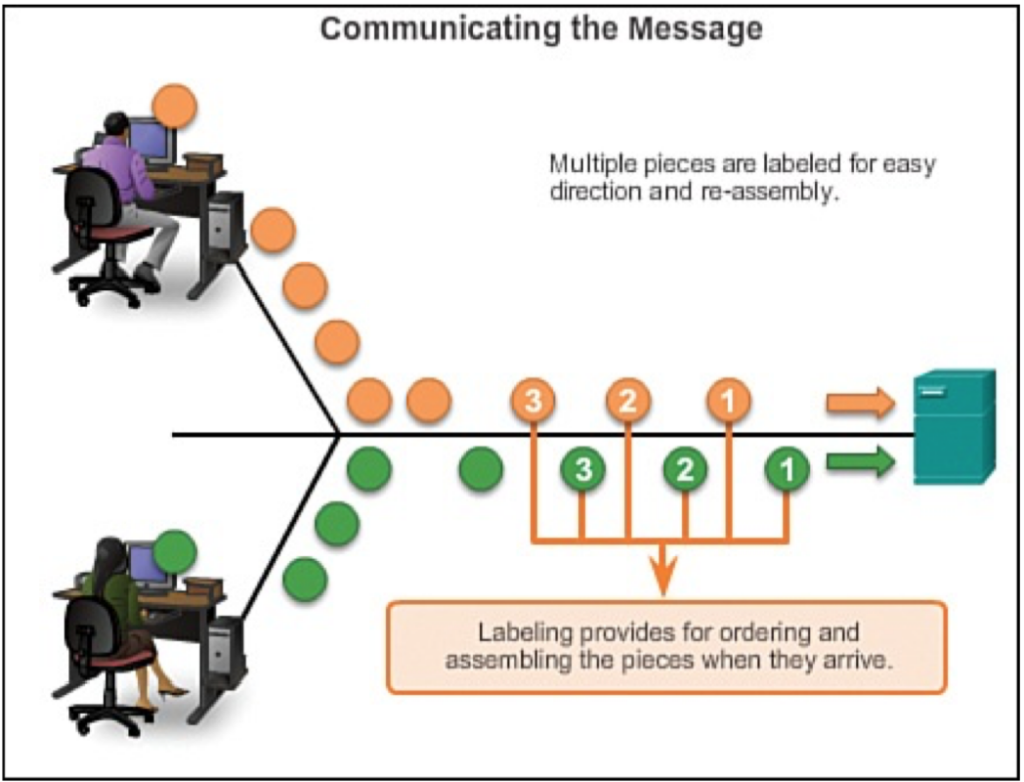
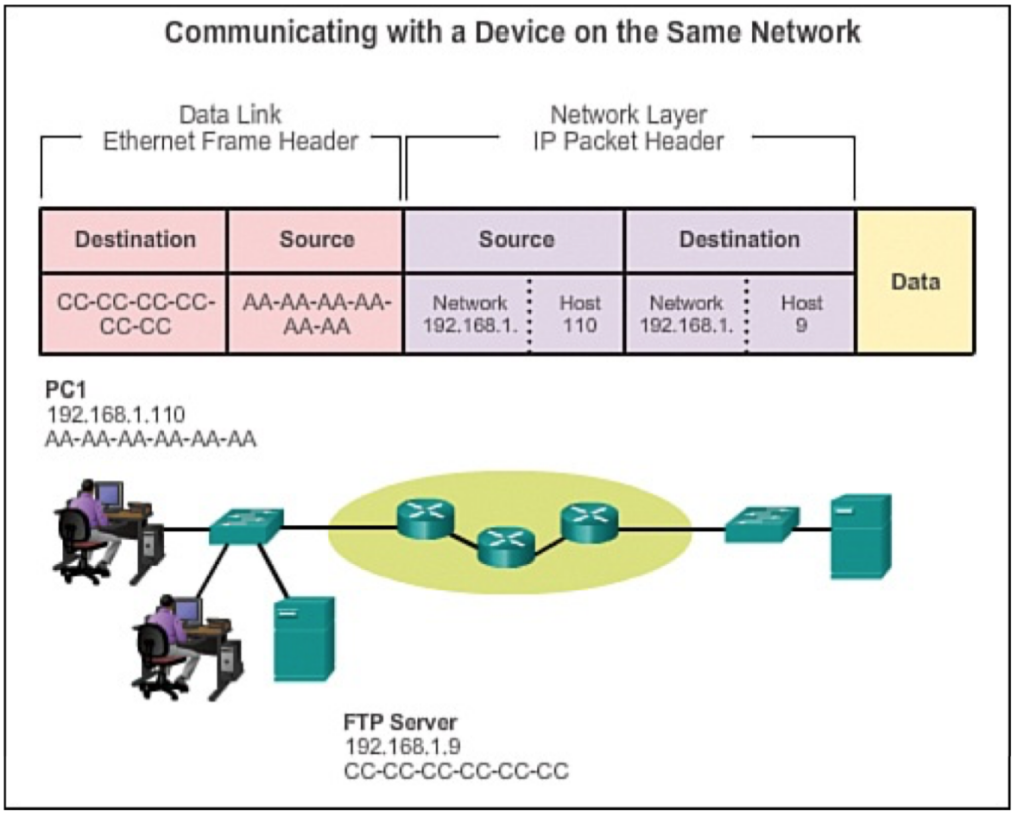
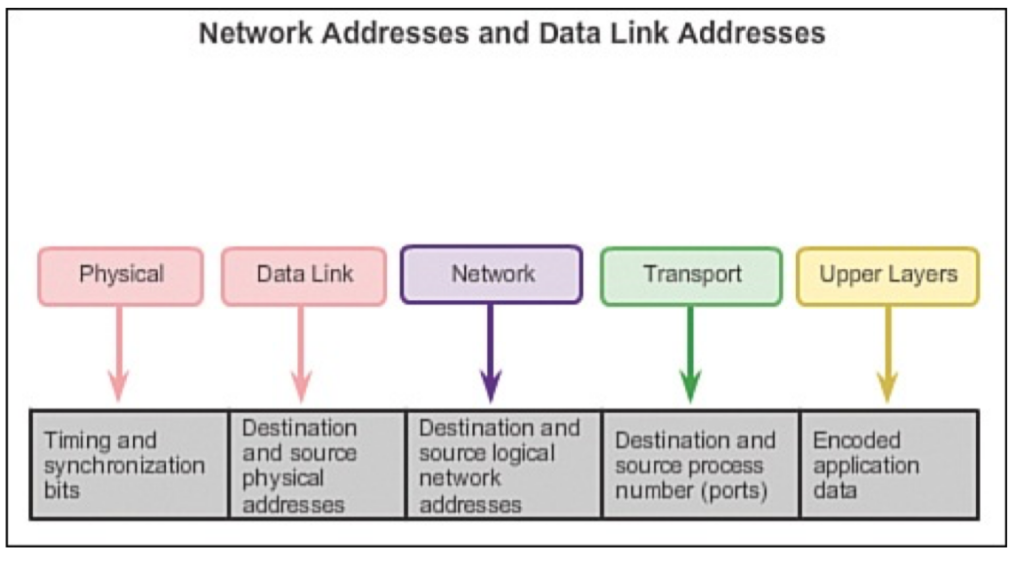
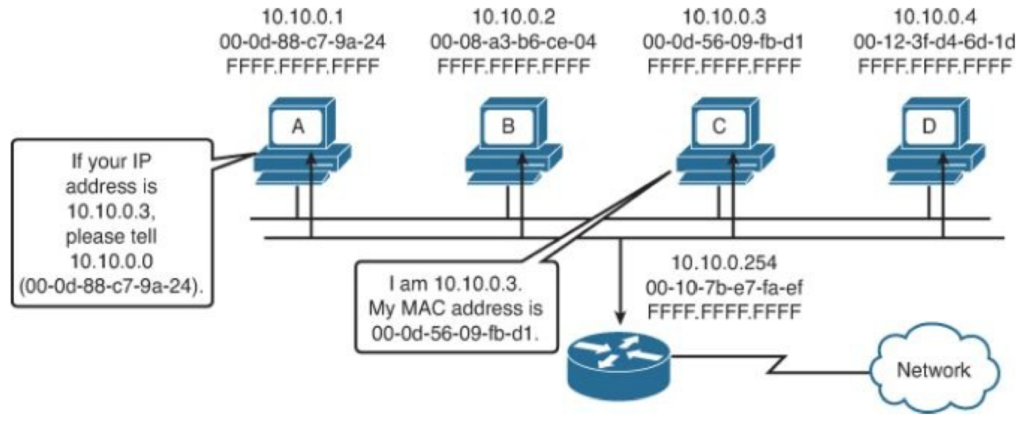
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
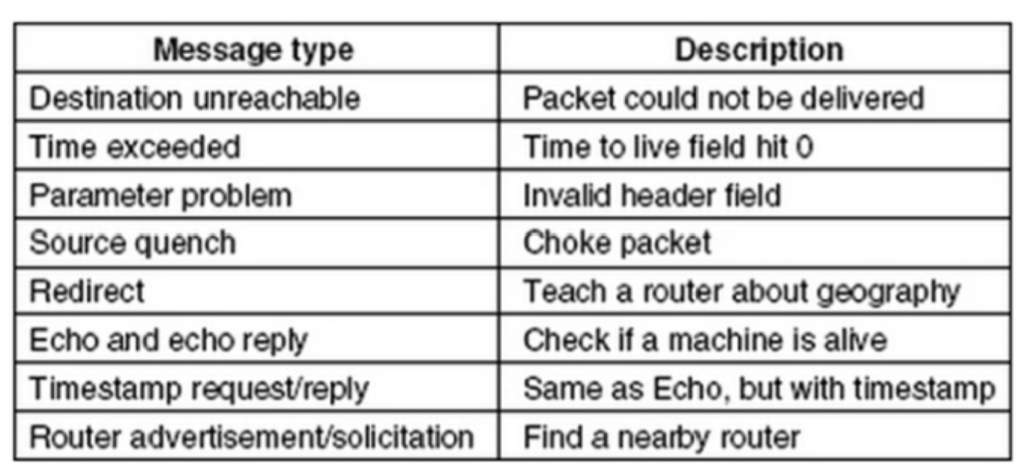
TIME EXCEEDED:由于报文TTL(Time to live)计数器到达0时。该事件是报文在回环,或计数器值设置过低的迹象。对于这一错误信息的聪明的应用是traceroute工具,traceroute发现从主机到目的IP地址路径上的路由器。它向目的地发送IP包,第一次的时候,将TTL设置为1,引发第一个路由器的Time Exceeded错误。这样,第一个路由器回复ICMP包,从而让出发主机知道途径的第一个路由器的信息。随后TTL被设置为2、3、4,…,直到到达目的主机。这样,沿途的每个路由器都会向出发主机发送ICMP包来汇报错误。traceroute将ICMP包的信息打印在屏幕上,就是接力路径的信息了。这并不是TIME EXCEEDED信息的本意,但却是非常有用的故障排查工具。
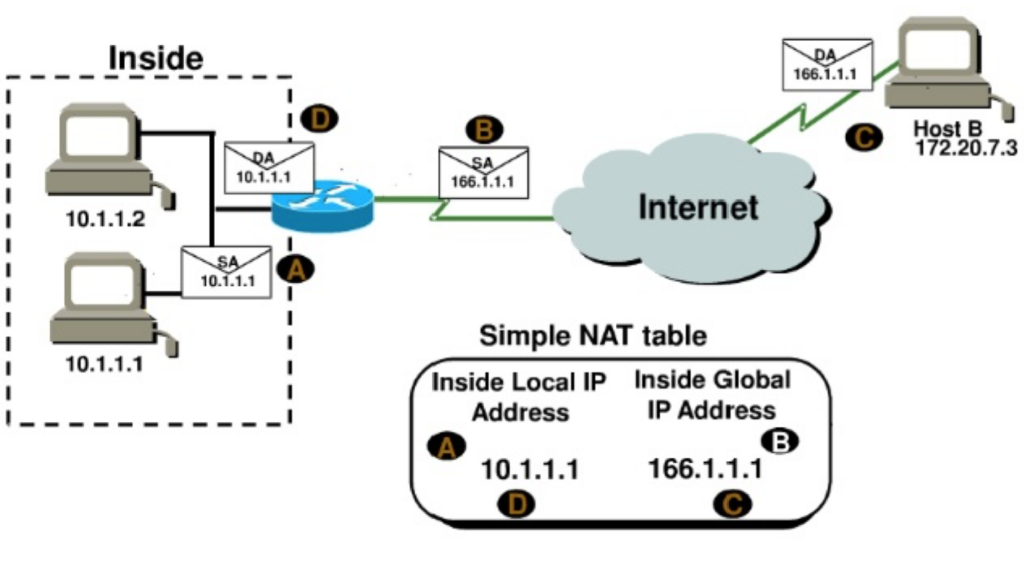
ip nat inside source static 10.1.1.1 170.46.2.2
interface Ethernet0
ip address 10.1.1.10 255.255.255.0
ip nat inside
interface Serial0
ip address 170.46.2.1 255.255.255.0
ip nat outside
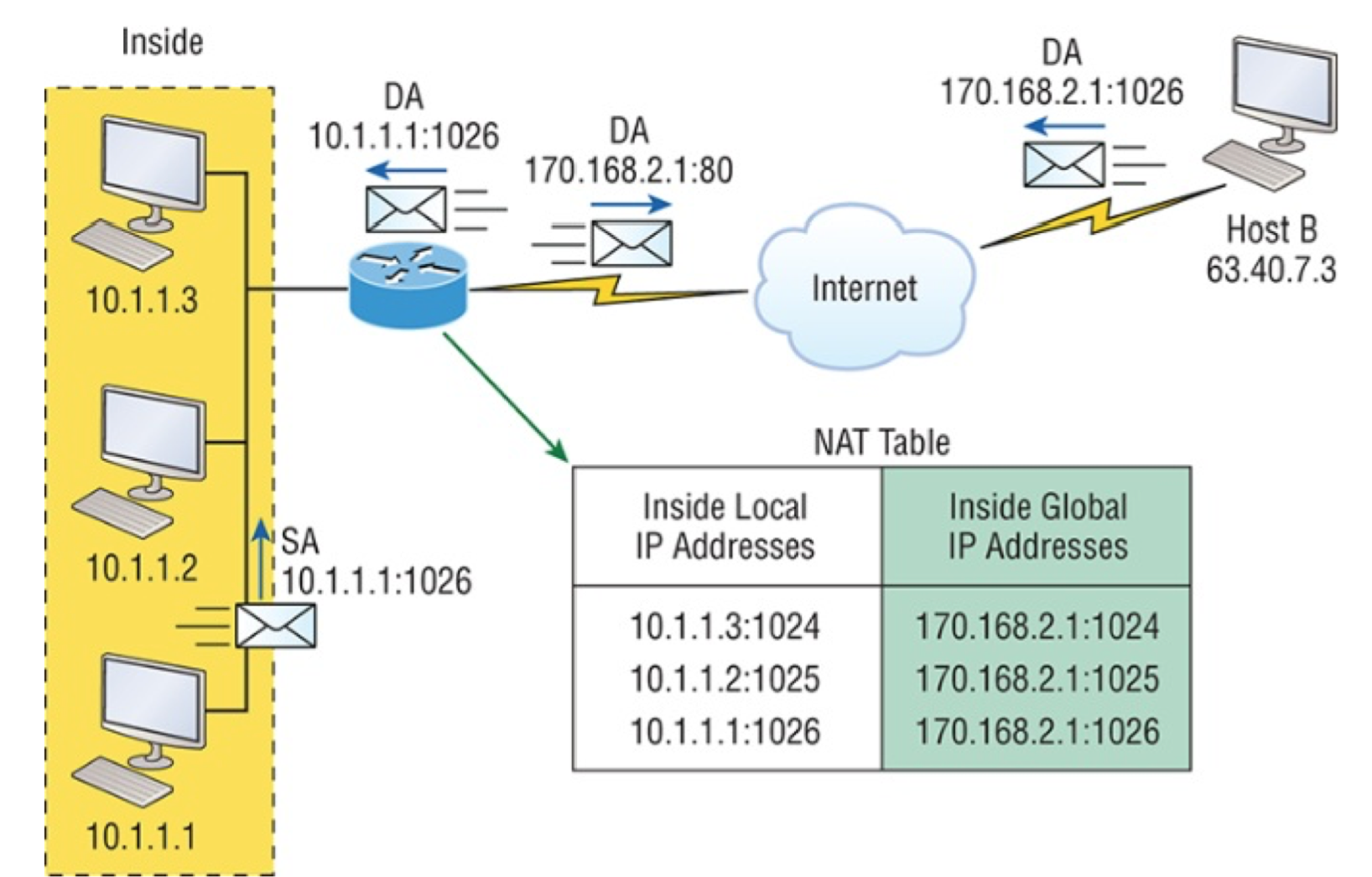
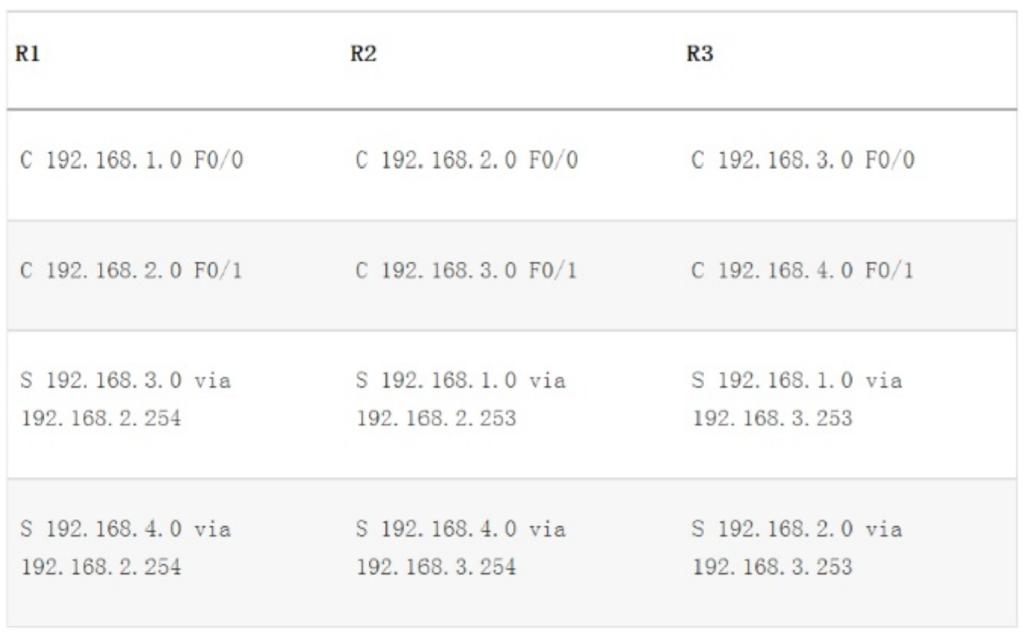
在第一个路由器输出中, ip nat inside source 命令指定需要转换的IP地址。本例中,此命令配置了内部本地IP地址10.1.1.1到外部全局IP地址170.46.2.2的静态配置。
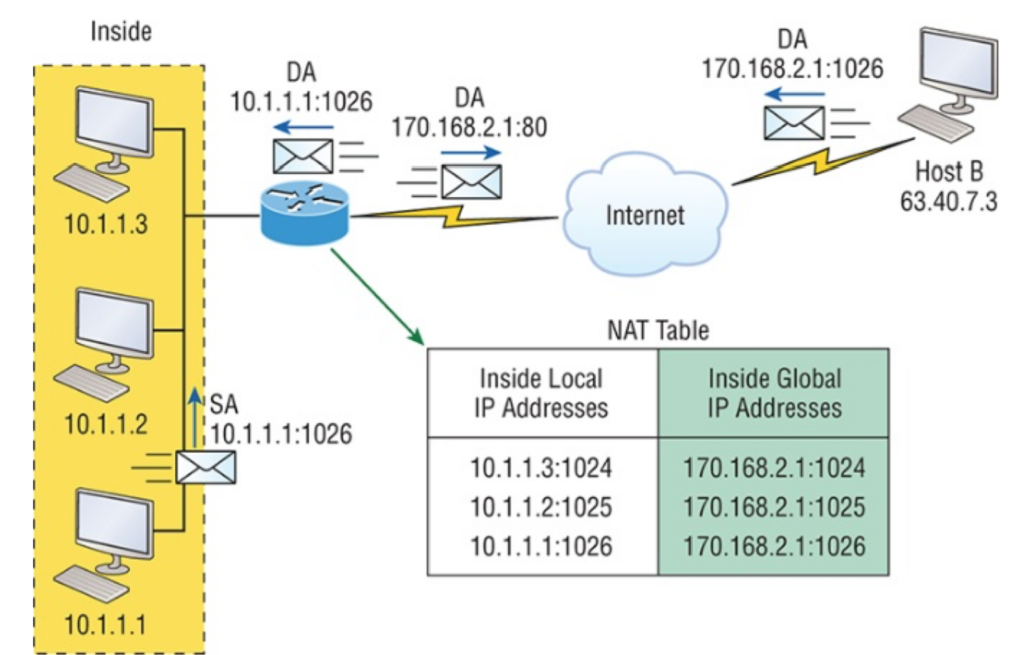
ip nat pool todd 170.168.2.3 170.168.2.254
netmask 255.255.255.0
ip nat inside source list 1 pool todd
interface Ethernet0
ip address 10.1.1.10 255.255.255.0
ip nat inside
interface Serial0
ip address 170.168.2.1 255.255.255.0
ip nat outside
access-list 1 permit 10.1.1.0 0.0.0.255
ip nat inside source list 1 pool todd 命令告知路由器将匹配access-list 1的IP地址转换到名为todd的IP NAT池中的一个地址。这里ACL并不是出于安全因素通过允许或拒绝数据来过滤报文。本例中,它是用来选择或指定我们感兴趣的数据流。当数据流与接入列表相匹配,就被拉入NAT进程转换。
命令 ip nat pool todd 170.168.2.3 192.168.2.254 netmask 255.255.255.0用来创建地址池,之后被分配给请求全局地址的主机。做Cisco NAT故障排查时,一定要检查池中确保有足够地址提供转换给内部主机。最后,确保池名匹配,注意区分大小写。
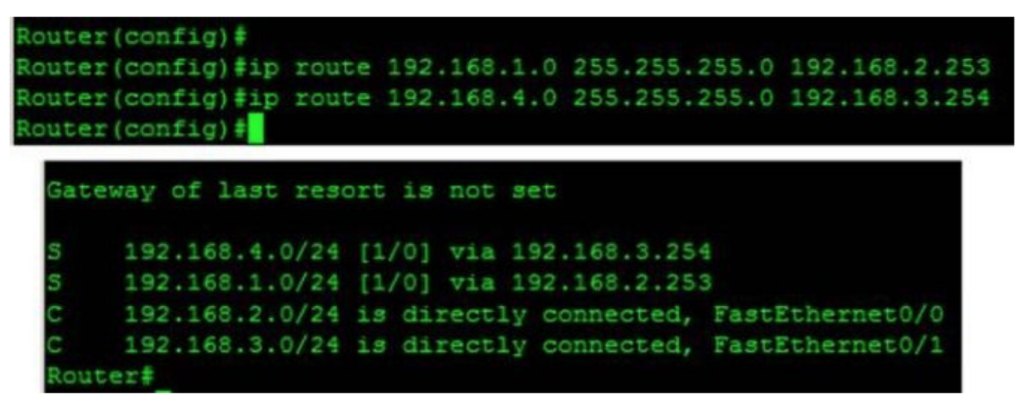
端口NAT配置:
以下是端口NAT配置的示例输出:
ip nat pool globalnet 170.168.2.1 170.168.2.1 netmask 255.255.255.0
ip nat inside source list 1 pool globalnet overload
interface Ethernet0/0
ip address 10.1.1.10 255.255.255.0
ip nat inside
interface Serial0/0
ip address 170.168.2.1 255.255.255.0
ip nat outside
access-list 1 permit 10.1.1.0 0.0.0.255
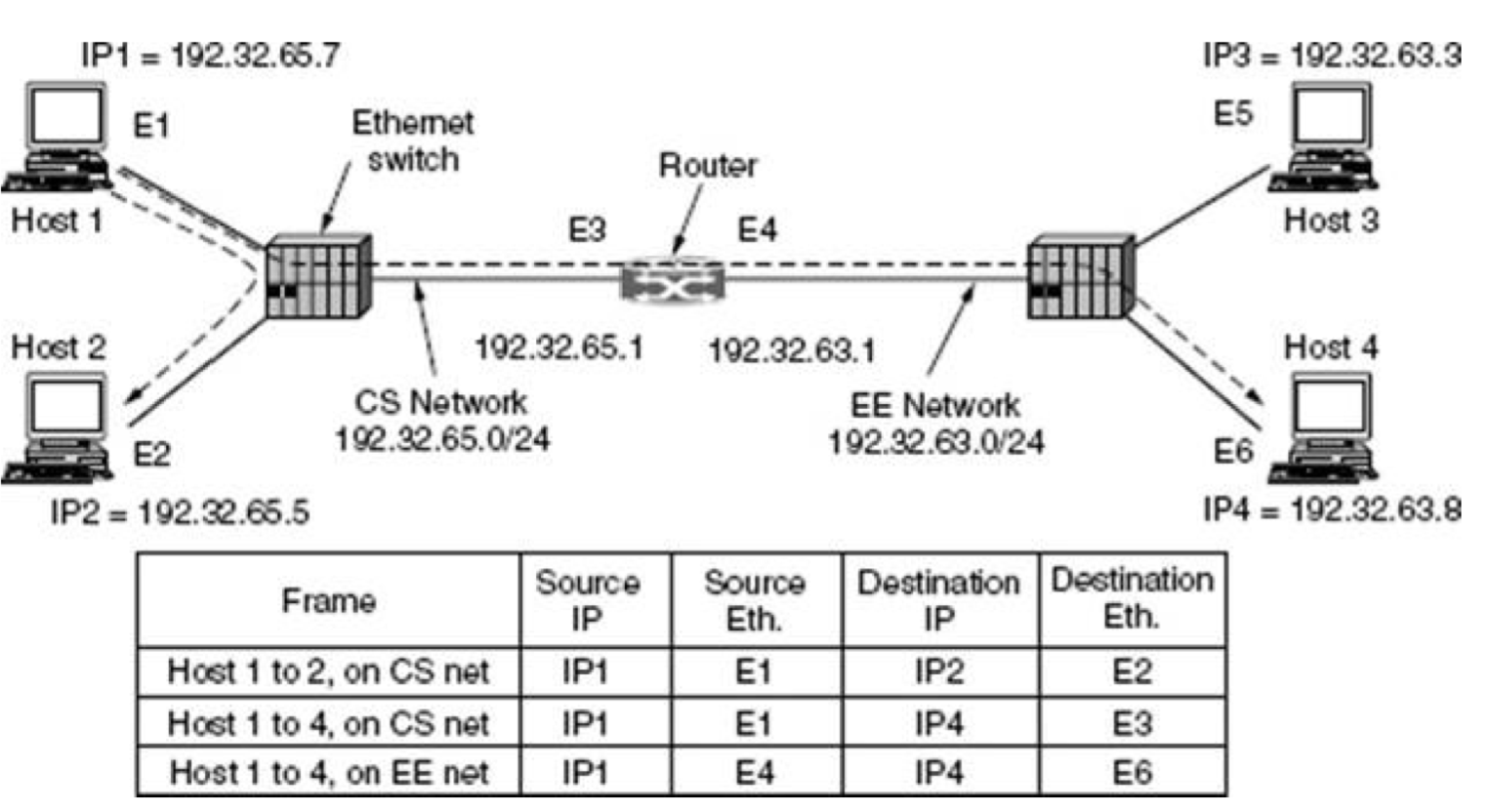
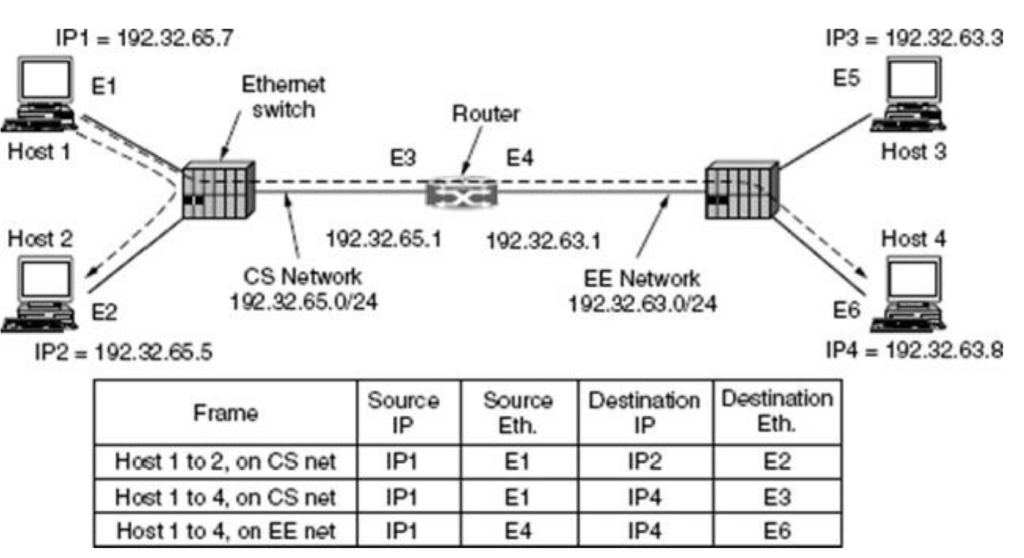
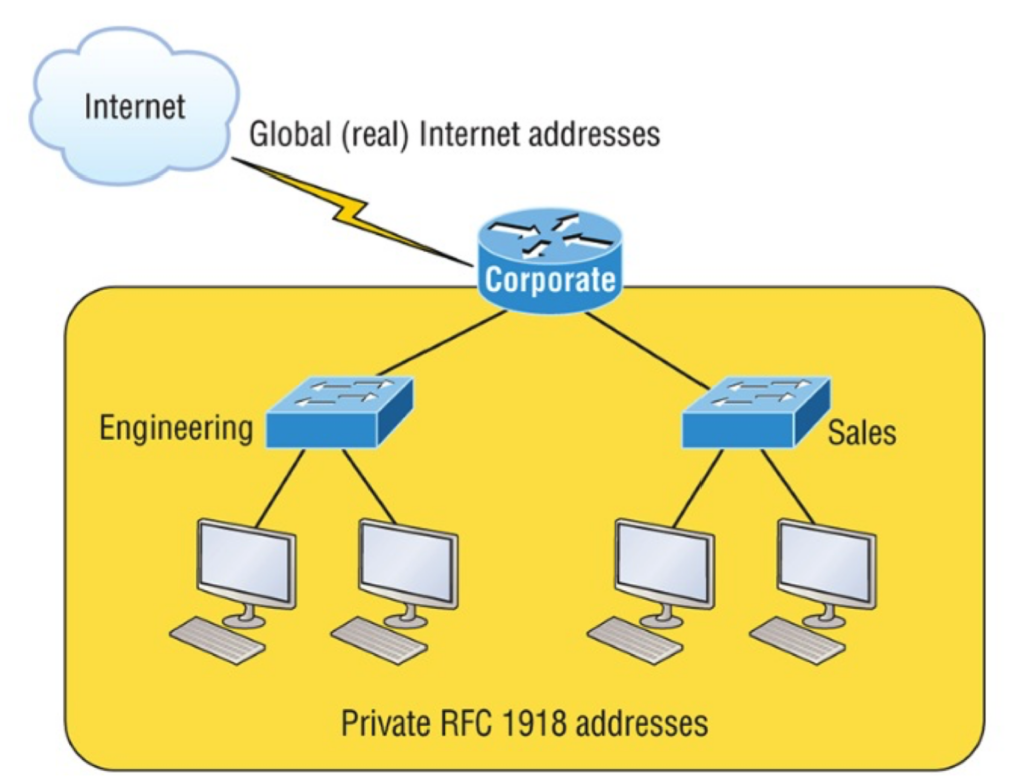
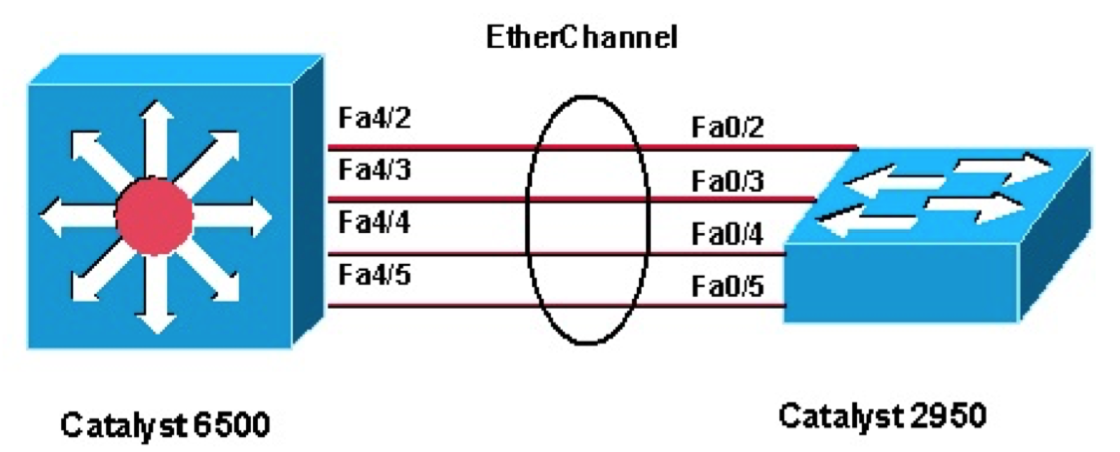
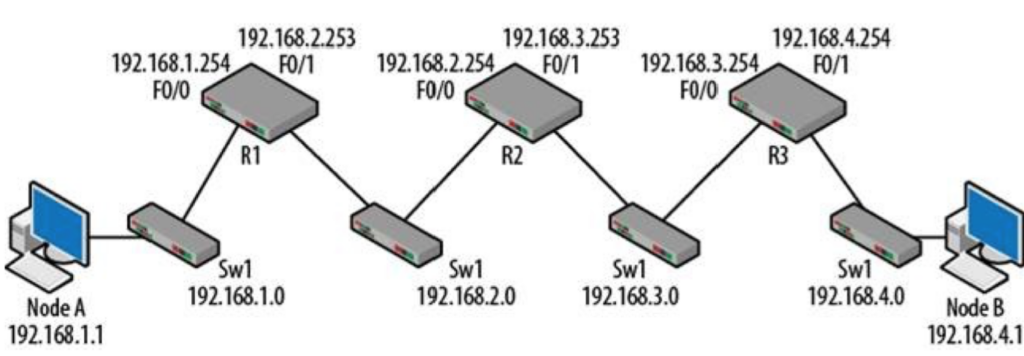
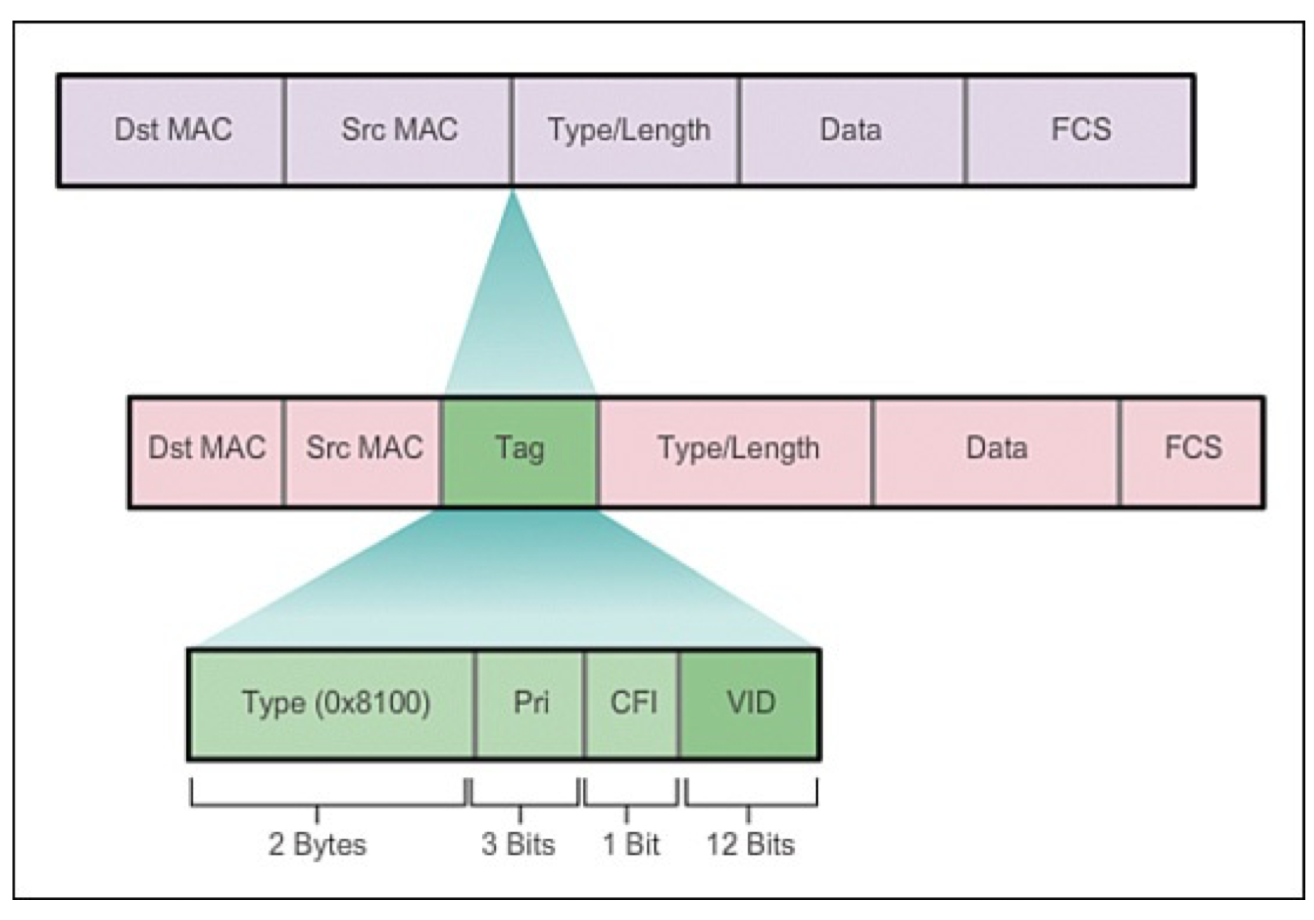
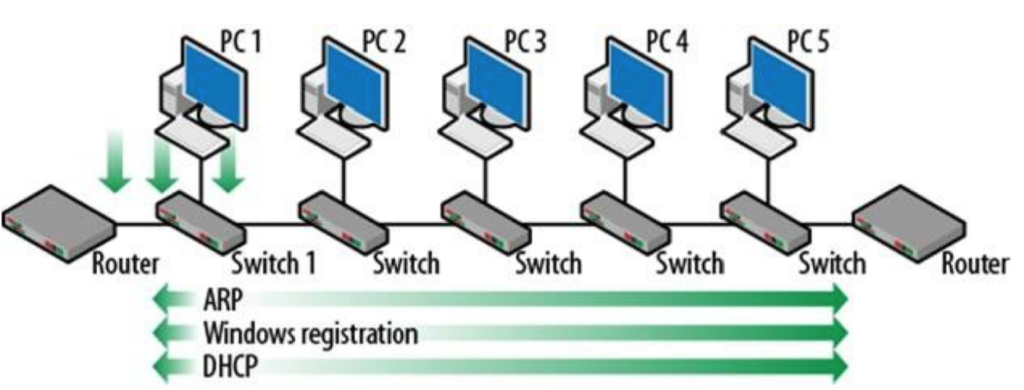
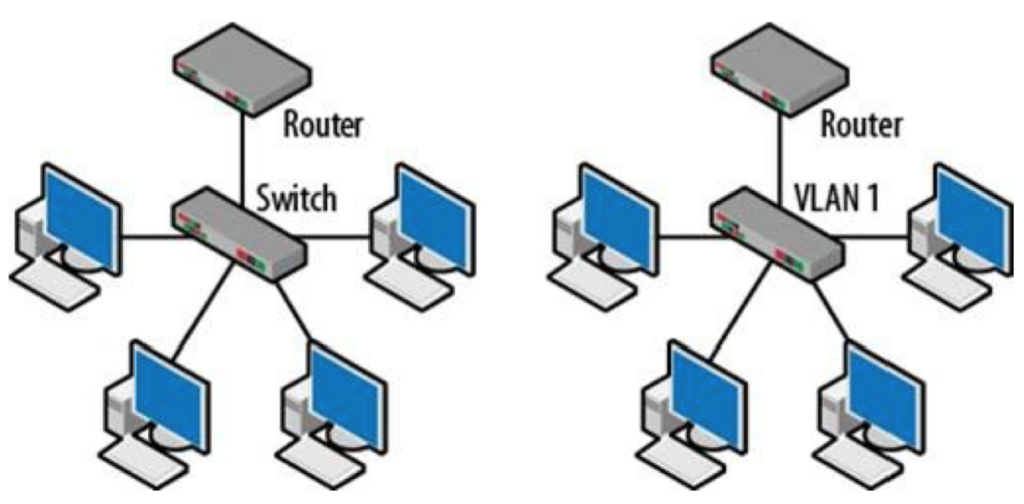
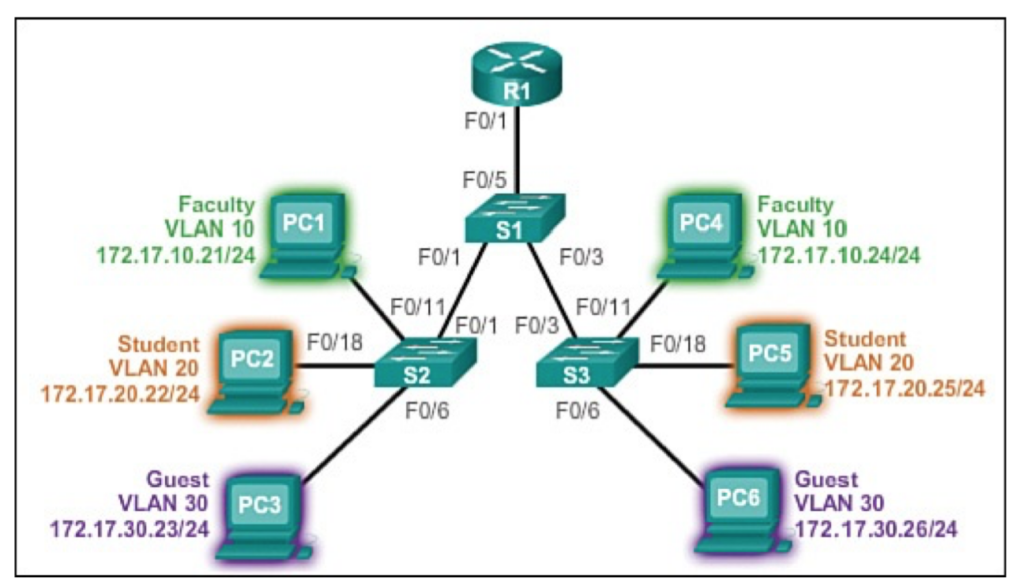
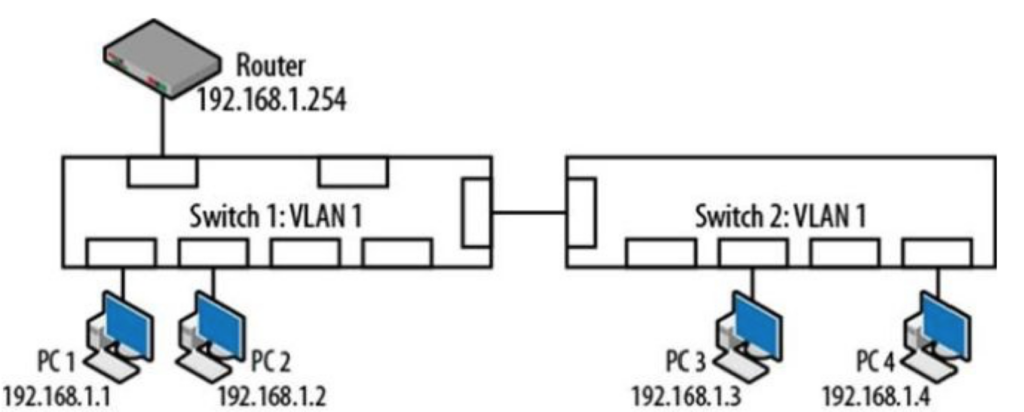
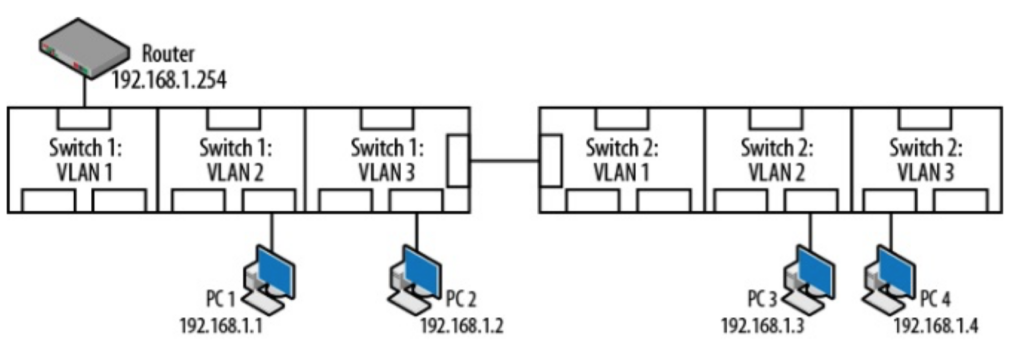
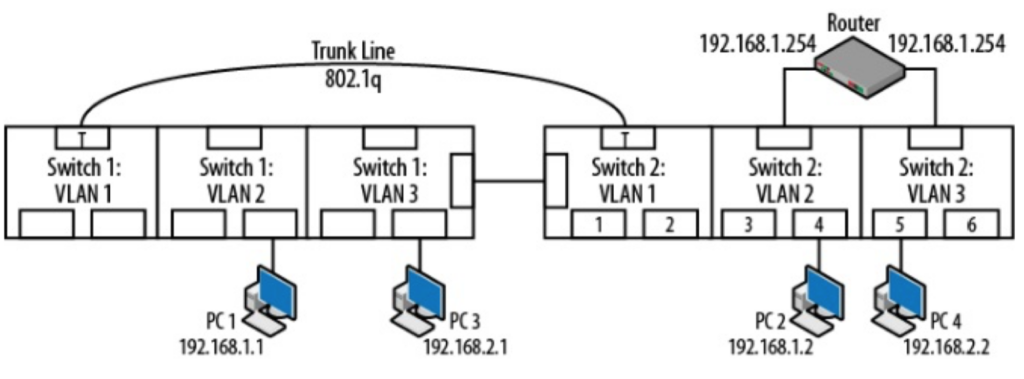
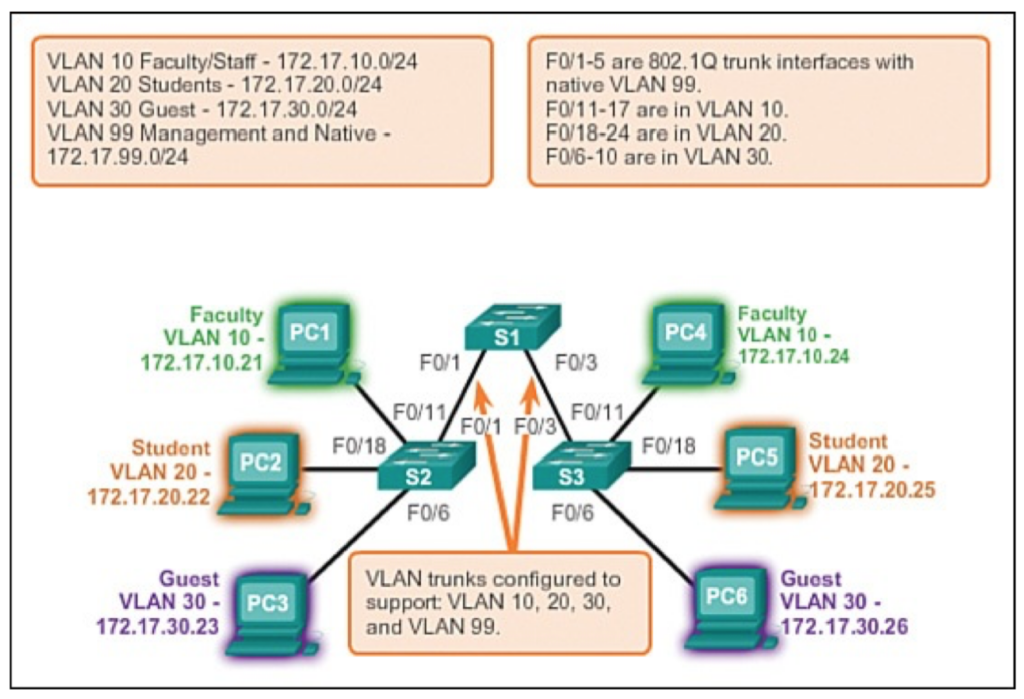
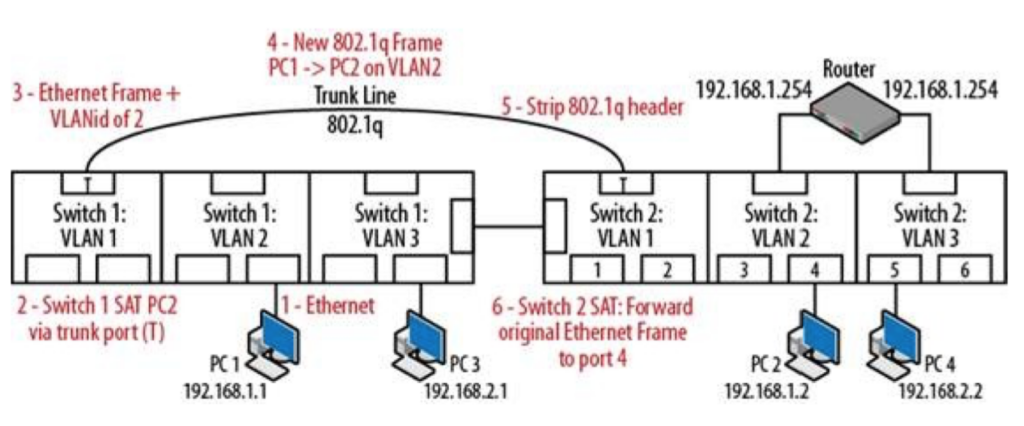
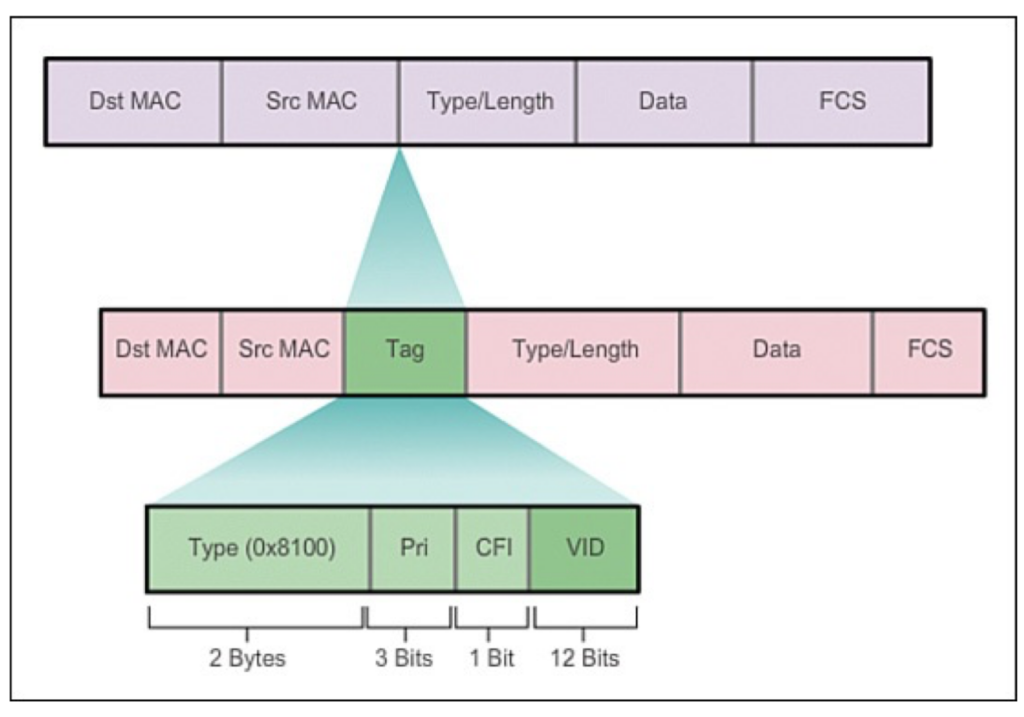
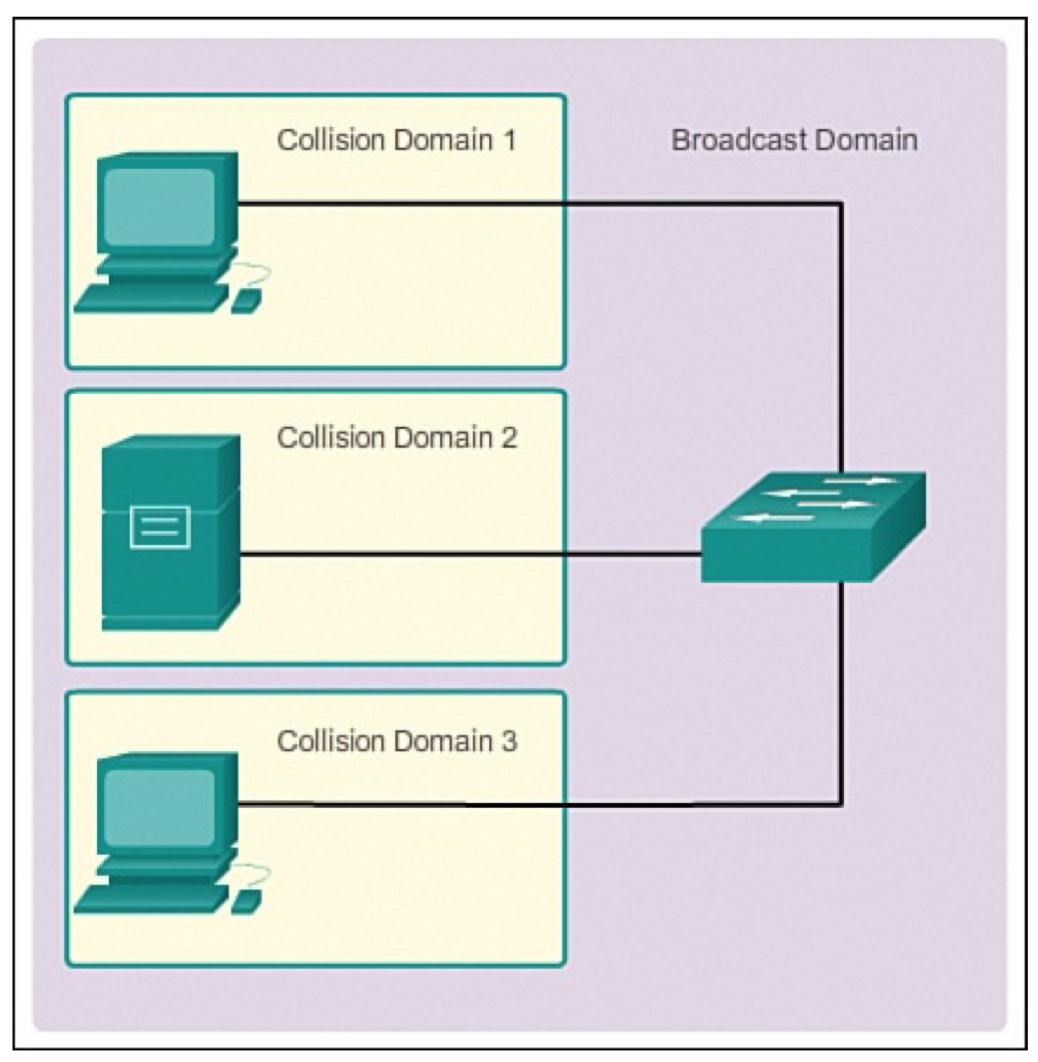
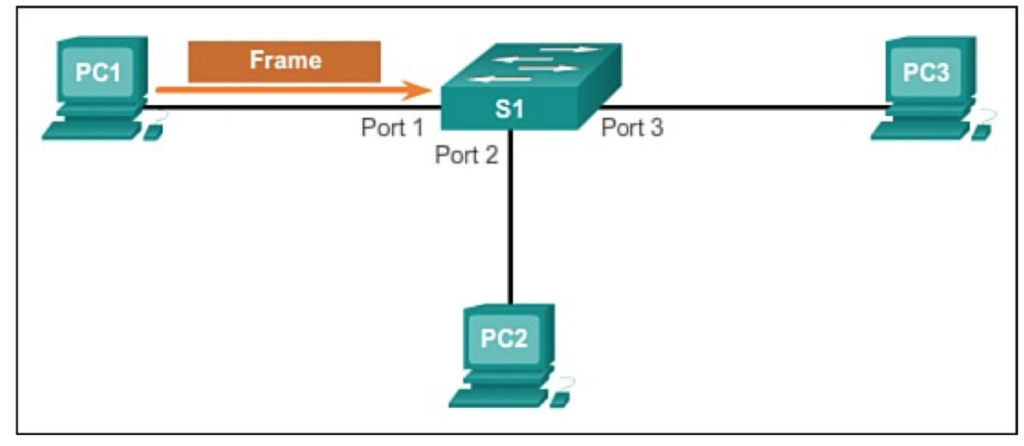
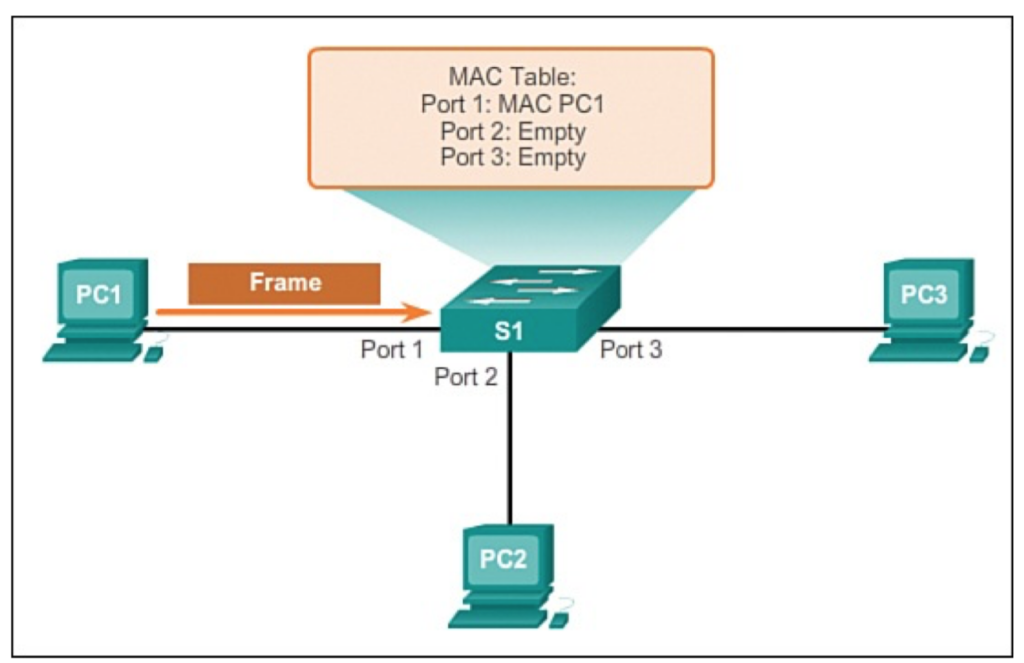
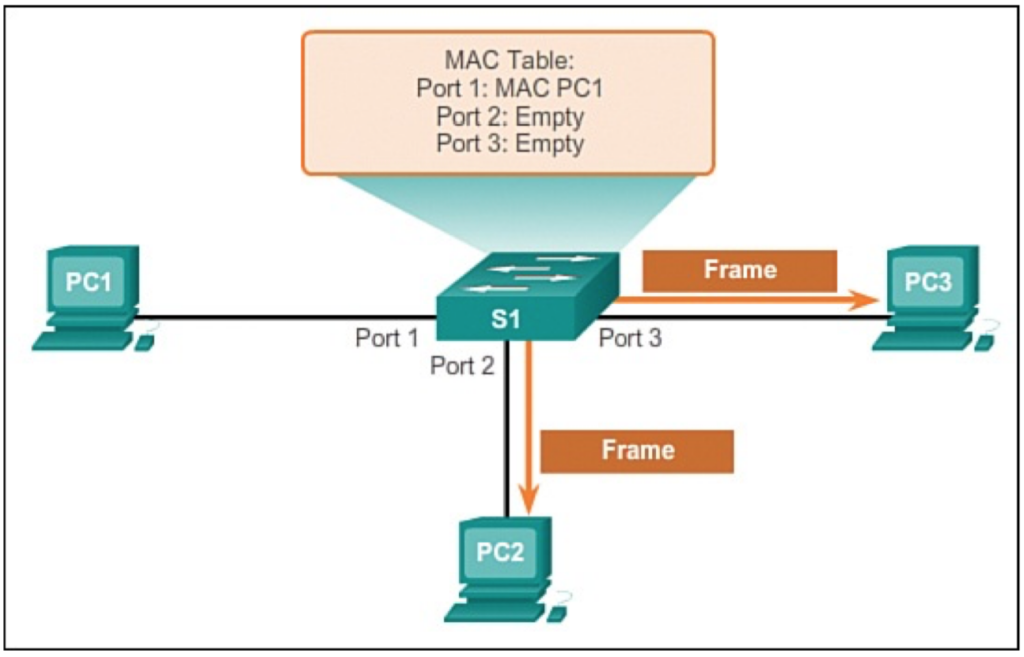
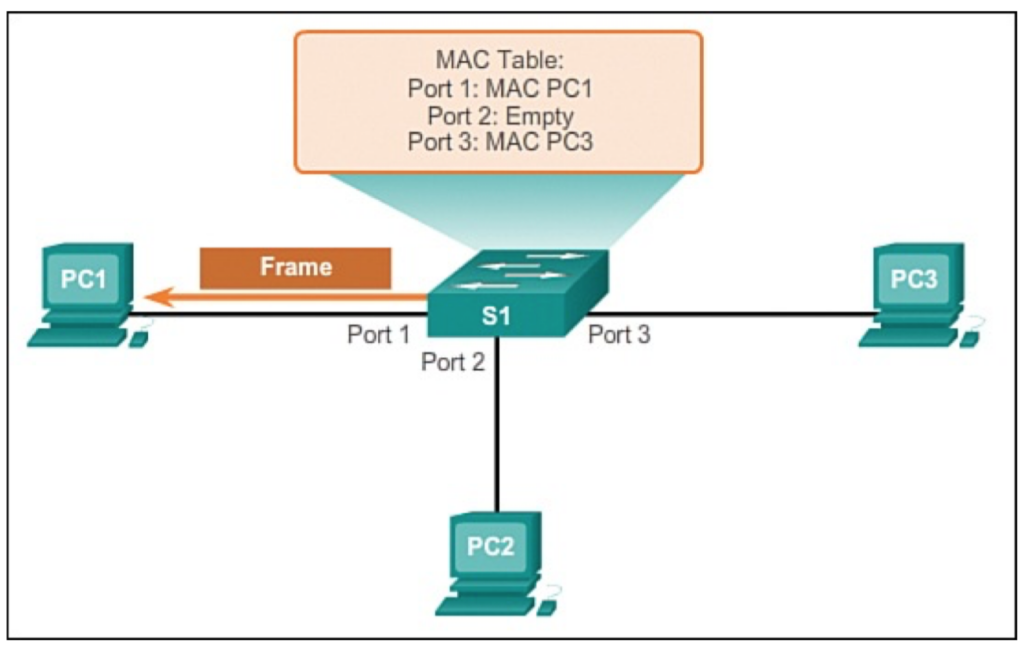
VLAN(virtual local area network)是一组与位置无关的逻辑端口。VLAN就相当于一个独立的三层网络。VLAN的成员无需局限于同一交换机的顺序或偶数端口。下图显示了一个常规的部署,左边这张图节点连接到交换机,交换机连接到路由器。所有的节点都位于同一IP网络,因为他们都连接到路由器同一接口。